小中高校生向け親子AI&量子コンピュータプログラミング解説会
データサイエンスと量子コンピュータに関しての説明をします。
資料は勉強会ではPDFでも提供しています。
ここでは、簡単なデータの扱い方と量子コンピュータのプログラミングを行います。
本ファイルはjupyternotebookという方式で書かれていて、blueqat cloudでしたら、ページにある自動取り込みボタンを押せば、クラウドに導入されます。
量子コンピュータプログラミング
データサイエンスに行く前に簡単に量子コンピュータのプログラミングだけを見てみたいと思います。
量子コンピュータはものすごい小さい「つぶ」と「なみ」を切り替えて計算をします。
#ツールの読み込み。
from blueqat import Circuit
Circuit().h[0].m[:].run(shots=100)
Counter({'1': 47, '0': 53})
これは量子コンピュータの最も簡単なプログラミングで、hゲートを使います。普通は0とか1とか答えは計算ごとに同じ答えが出ますが、これは0と1が半分ずつ出るけいさんです。かさねあわせとよびます。
量子テレポーテーション
量子テレポーテーションは人間がテレポートするわけではありません。数字がテレポートします。
今回は簡単な量子回路を使って数字をテレポートさせます。
a = Circuit().h[1].cx[1,2].cx[0,1].h[0].cx[1,2].cz[0,2].m[:]
a.run(shots=100)
Counter({'110': 23, '010': 30, '100': 24, '000': 23})
こちらが基本的な量子テレポーテーション回路です。みるべきものは、一番最後の数字となっていて、最後が全部0になっています。これは本当は一番最初にあった数字が最後に移動しています。そういう意味で量子テレポーテーションです。つぎに1を最後に移動させてみましょう。
(Circuit().x[0] + a).run(shots=100)
Counter({'011': 26, '111': 22, '001': 27, '101': 25})
これもきちんと最後の数字が1になっています。
(Circuit().h[0] + a).run(shots=100)
Counter({'011': 9,
'110': 21,
'001': 15,
'101': 17,
'100': 11,
'010': 14,
'000': 7,
'111': 6})
重ね合わせに量子テレポーテーションをかけてもやっぱりちゃんと最後の数字に反映されています。
量子コンピュータのかんたんな説明は以上です。次はデータサイエンスを見てみたいと思います。
将来的な量子コンピュータアプリ
実は将来的な量子コンピュータのアプリも今のコンピュータで必要とされるアプリとあまり変わりません。量子コンピュータを使ってより速い計算やより安く計算をしたいという要望がありますが、それらは今のコンピュータの延長線上でとらえることも可能になっています。
ここでは、今量子コンピュータで将来的に最も期待されているAI分野でのアプリにフォーカスしてみたいと思いますが、2022年段階では普通のコンピュータでそのようなデータを学ぶのが効率的です。
量子コンピュータでもAIでも使われるプログラミング言語は同じです。私たちが今使っているpython(パイソン)という言語です。これを使うことにより、現在も未来も仕事をすることができます。ここでは、データサイエンスの基本であるよそくをやってみたいと思います。
データサイエンスでポケモンガオーレのポケエネを当てる
データはいえに散らかっていたポケモンガオーレディスクをつかいました。ポケモン10匹のデータを入力しておぼえさせます。
そのご、ポケエネを知りたいポケモンのデータを入れてあててみます。
まずはツールを読み込みます。pandasというツールを使います。numpyは便利な計算がたくさん入っているツールです。
import pandas as pd
import numpy as np
#データを準備しました。
data = np.array([ #ポケエネ、#たいりょく,#こうげき、#ぼうぎょ、#とっこう、#とくぼう、#すばやさ
[96,107,78,54,78,54,104], #パルスワン
[110,125,110,81,96,62,72], #アップリュー
[114,118,108,128,61,66,94], #リーフィア
[94,113,54,54,79,84,82], #フォクスライ
[96,119,104,80,63,72,40], #オトスパス
[124,122,101,85,125,101,85], #パルキア
[104,110,76,59,93,76,105], #ジュカイン
[66,91,65,38,38,38,59], #ワルビル
[70,85,49,45,61,50,61], #マグマラシ
[84,98,64,80,64,80,34] #ビークイーン
])
df = pd.DataFrame(data,columns=['pokeene','tairyoku','kougeki','bougyo','tokko','tokubo','subayasa'])
df
pokeene tairyoku kougeki bougyo tokko tokubo subayasa
0 96 107 78 54 78 54 104
1 110 125 110 81 96 62 72
2 114 118 108 128 61 66 94
3 94 113 54 54 79 84 82
4 96 119 104 80 63 72 40
5 124 122 101 85 125 101 85
6 104 110 76 59 93 76 105
7 66 91 65 38 38 38 59
8 70 85 49 45 61 50 61
9 84 98 64 80 64 80 34
まずは、データから覚えさせたいポケエネのデータだけを分けます
#ポケエネだけのデータ
y = df["pokeene"]
#ポケエネ以外のデータ
X = df.drop(columns=["pokeene"], axis=1)
次に覚えさせるためのデータと、覚えさせないテスト用のデータを準備します。試験勉強では勉強した範囲とちょっと違う問題がでますよね。きちんと応用ができるかどうかを確かめるために、学習したデータにはテストのデータを入れないようにします。学習用のデータをtrain、テスト用のデータをvalとつけます。
これらの訓練用のデータを作るための便利ツールがあります。今回はsklearnという統計用のツールを使います。test_size=0.2は全体の20%をテストに回すという意味です。
from sklearn.model_selection import train_test_split
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=1)
X_train
tairyoku kougeki bougyo tokko tokubo subayasa
6 110 76 59 93 76 105
4 119 104 80 63 72 40
0 107 78 54 78 54 104
3 113 54 54 79 84 82
1 125 110 81 96 62 72
7 91 65 38 38 38 59
8 85 49 45 61 50 61
5 122 101 85 125 101 85
こんな感じでできました。さっそくこれらのデータをおぼえさせてみます。
今回はxgboostというツールを使って覚えさせます。まずインストールをします。
!pip install xgboost
Requirement already satisfied: xgboost in /opt/conda/lib/python3.8/site-packages (1.5.2)
Requirement already satisfied: numpy in /opt/conda/lib/python3.8/site-packages (from xgboost) (1.20.3)
Requirement already satisfied: scipy in /opt/conda/lib/python3.8/site-packages (from xgboost) (1.6.3)
完了したらさっそく使えます。
学習にはいろいろな方法がありますが、それらの学習する方法をmodelといいます。
そして、modelにデータを学習させます。学習はfitを使います。
学習には、問題と答えがあり、X_trainが問題、y_trainが答えに相当します。
# xgboost
import xgboost as xgb
model = xgb.XGBRegressor(n_estimators=1000, learning_rate=0.01)
model.fit(X_train, y_train)
XGBRegressor(base_score=0.5, booster='gbtree', colsample_bylevel=1,
colsample_bynode=1, colsample_bytree=1, enable_categorical=False,
gamma=0, gpu_id=-1, importance_type=None,
interaction_constraints='', learning_rate=0.01, max_delta_step=0,
max_depth=6, min_child_weight=1, missing=nan,
monotone_constraints='()', n_estimators=1000, n_jobs=2,
num_parallel_tree=1, predictor='auto', random_state=0, reg_alpha=0,
reg_lambda=1, scale_pos_weight=1, subsample=1, tree_method='exact',
validate_parameters=1, verbosity=None)
これで学習が終わりました。ちょっと今回はval使いませんでしたが、いきなりテストに行こうと思います。
問題は、
たいりょく96,こうげき66,ぼうぎょ55,とっこう48,とくぼう55,すばやさ41のヌマクローのデータをつかってポケエネをあててみます
X_test = np.array([[96,66,55,48,55,41]])
predictions = model.predict(X_test)
predictions[0]
69.99208
いかがでしょうか。70くらいとでました。正解は72となっていますので、大体近いすうじがでてますね。次になんの数字がポケエネをあてるのにつかえるかをみてみます。
xgb.plot_importance(model)
<AxesSubplot:title={'center':'Feature importance'}, xlabel='F score', ylabel='Features'>
<Figure size 432x288 with 1 Axes>
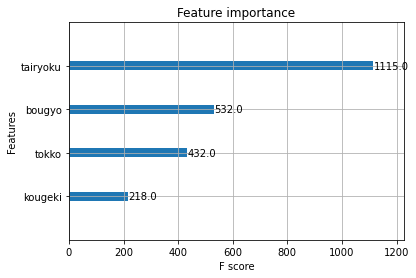
これを見ると、たいりょくが一番だいじとなります。こういうふうにデータを使って学ぶことができますが、今のコンピュータでも量子コンピュータでもやることは基本的には変わりません。
おまけ
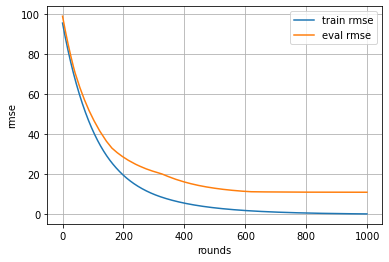
AIがデータを覚えるようすをみる
evals_result = {}
model = xgb.XGBRegressor(n_estimators=1000, learning_rate=0.01)
model.fit(X_train, y_train,eval_set=[(X_train, y_train),(X_val, y_val)],
eval_metric='rmse',callbacks=[xgb.callback.record_evaluation(evals_result)],verbose=0)
import matplotlib.pyplot as plt
#trainデータに対してのloss推移をplot
plt.plot(evals_result['validation_0']['rmse'], label='train rmse')
#testデータに対してのloss推移をplot
plt.plot(evals_result['validation_1']['rmse'], label='eval rmse')
plt.grid()
plt.legend()
plt.xlabel('rounds')
plt.ylabel('rmse')
plt.show()
<Figure size 432x288 with 1 Axes>