こんにちは。歳をとってしまったため、気圧の変化に弱くなって苦労しています。
今回はcuQuantumの中でも特徴的なアップデートである、ホストステートベクターマイグレーションについて確認したいと思います。
量子コンピューターのシミュレーションのうち、すべての量子状態をベクトルに保存するものを状態ベクトルシミュレーションといいます。 状態ベクトルシミュレーションの保存するベクトルのサイズは、量子ビット数Nに対して2のN乗です。 こうした状態ベクトルを計算の途中に全て保存しながら計算するというのは大変にメモリを消費します。また最近GPUが流行っていて、今回利用するcuQuantumでGPUを利用した状態ベクトルのシミュレーションを行うために重要になってくるのは、GPUに搭載されているメモリの量となっていて、基本的に私たちの現在計算しているものに関しては、GPUメモリが足りないと言う場面が多いかと思います。
状況は少し変わり、最近NVIDIA社がCPUを出すという話になっています。
NVIDIA Grace CPU
https://www.nvidia.com/ja-jp/data-center/grace-cpu/
ということで、今回はCPUとGPUの間でこうしたメモリを消費する状態ベクトルをどういう風にやり取りするかと言うことに関して、エヌビディアがCPUに進出したことによって新しいAPIが開発されています。それを見てきたいと思います。
cuStateVecライブラリは、custatevecSubSVMigrator APIを提供しており、これを利用することでユーザーはホストCPUメモリとデバイスGPUメモリを連携させ、シミュレーションのスケールを拡大することができます。
custatevecSubSVMigrator API
custatevecSubSVMigrator APIは、CPU(ホスト)上に割り当てられた状態ベクトルを、さらにGPU(デバイス)上にも移行するためのユーティリティです。このAPIを使用すると、CPUメモリを活用して状態ベクトルを収容することができます。また、CPUとGPUの両方のメモリを使用して、シミュレートする量子ビットの数を最大化するために、単一の状態ベクトルを割り当てることもできます。
custatevecSubSVMigrator APIのメモリモデル
custatevecSubSVMigrator APIは、図1に示されたメモリモデルを想定しています。状態ベクトルは、一連のサブ状態ベクトルに均等に分割されるとされています。サブ状態ベクトルの数は、常に2のべき乗です。各サブ状態ベクトルは、ホストまたはデバイススロットに配置されます。
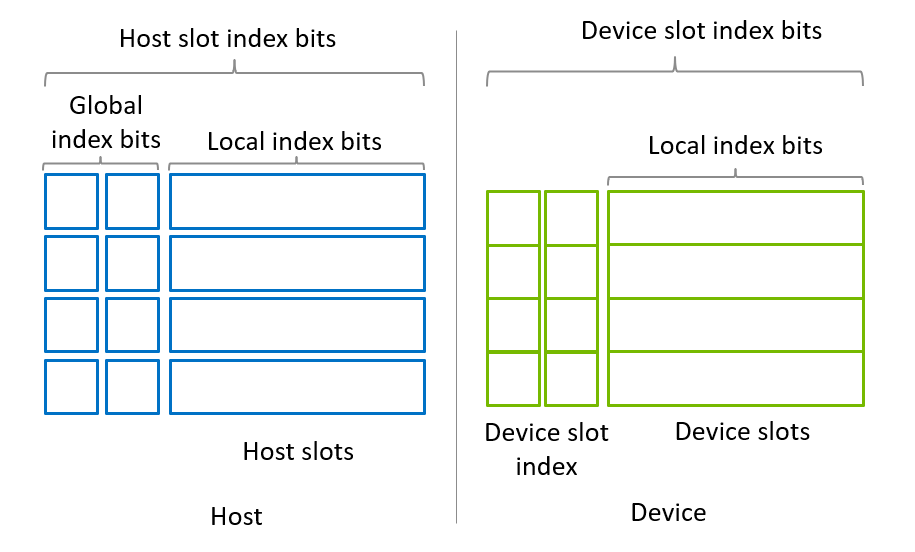
図1、引用:https://docs.nvidia.com/cuda/cuquantum/latest/custatevec/host_state_vector_migration.html
サブ状態ベクトルは部分状態を表し、一部の量子ビットのサブセットに対応するローカルインデックスビットを持ちます。そのサイズは、ローカルインデックスビットの数がnである場合、(当然ですが)2^nです。
1つの要件は、ホストスロットがデバイスから直接アクセス可能でなければならないということです。これは、HMM(別の機会にブログ書こうかと思います)を使用しないx86プラットフォーム上でCUDAピンメモリを割り当てるために cudaHostAlloc() を使用することを意味します。GH200などの他のシステムでは、malloc() を使用して割り当てられたメモリチャンクがデバイスからアクセス可能であるため、CUDAピンメモリを割り当てることは必須ではありません。各ホストスロットは独自のメモリチャンクを持つことができるか、単一の連続したメモリチャンクとして割り当てることができます。
デバイススロットは、すべてのデバイススロットが連続して配置される単一のデバイスメモリチャンクとして割り当てる必要があります。これにより、デバイススロットを部分状態ベクトルの単一のチャンクとして利用することが可能になります。この構成により、デバイススロットインデックスビットに対する操作(例えばゲートの適用)はデバイススロットで実行されます。したがって、デバイススロットの数は常に2のべき乗です。
cuStateVecライブラリでは、このモデルは custatevecSubSVMigratorDescriptor_t によって表され、custatevecSubSVMigratorCreate() によって作成され、custatevecSubSVMigratorDestroy() によって破棄されます。
インデックスビットスワップは、cuStateVecのインデックスビットをローカライズするためのアルゴリズムであり、分散インデックスビットスワップAPIドキュメントの量子ビットの再配置と分散インデックスビットスワップで説明されています。サブ状態ベクトルを移行する際、インデックスビットは custatevecSubSVMigrator API および custatevecSwapIndexBits() を使用して、このドキュメントの後半のセクションで説明されるようにスワップされます。
---------------
ホストメモリを使用して状態ベクトルを割り当てる際に考えられる2つのシナリオがあります。
ホスト上に状態ベクトルを割り当てる
ホストメモリの容量が全ての状態ベクトルを保持するのに十分である場合、ホストスロット上に状態ベクトルを割り当て、デバイススロットを使用して操作を適用することができます。シミュレーション中には、サブ状態ベクトルがデバイススロットにコピーされ(チェックアウト)、操作を適用した後、状態ベクトルがホストスロットに戻されます(チェックイン)。この移行ステップは、すべてのサブ状態ベクトルに対して操作を適用するために繰り返されます。
ホストとデバイスの両方で状態ベクトルを割り当てる
可能な限り多くのホストおよびデバイスメモリを利用するため(最大の状態ベクトルを割り当てるため)、ホストとデバイスの両方のメモリを使用して状態ベクトルを割り当てることができます。操作はデバイス上で適用され、サブ状態ベクトルはホストとデバイス間でスワップされ、すべてのサブ状態ベクトルに対して操作が適用されます。
---------------
1. ホストスロット上に状態ベクトルを割り当てる場合
図2は、ホストスロット上に割り当てられたサブ状態ベクトルの簡略化された例を示しています。4つのサブ状態ベクトルがホストスロットに配置され、2つのデバイススロットが割り当てられて空のまま保持されています。pおよびqと表記される2つのグローバルインデックスビットがあります。
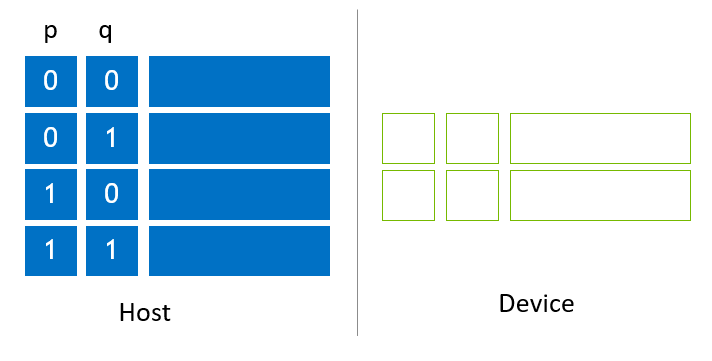
図2、引用:https://docs.nvidia.com/cuda/cuquantum/latest/custatevec/host_state_vector_migration.html
NVIDIA H100 (80G) を使用し、図2に示されるようにデバイススロットにメモリを割り当てる場合、デバイススロットのサイズは64GBで、各スロットのサイズは32GBです。ホスト状態ベクトルのサイズはそれの2倍であり、したがってホスト状態ベクトルのサイズは128GBです。NVIDIA H100 (80G) での最大状態ベクトルサイズは、それぞれ33キュービット(c64)および32キュービット(c128)です。128GBのホストメモリを使用することで、最大状態ベクトルサイズは1増加し、それぞれ34キュービット(complex64)および33キュービット(complex128)になります。
SubStateVectorMigrator APIを使用すると、以下のプリミティブを使用してサブ状態ベクトルが移行します。これらのプリミティブを組み合わせることで、グローバルおよびローカルインデックスビットが適切に並び替えられます。
1.ホストスロットのサブ状態ベクトルをデバイススロットにチェックアウトする。
ホストスロット上のホストサブ状態ベクトルをデバイススロットにコピーする。この操作は、custatevecSubSVMigratorMigrate() の srcSubSV 引数にホストスロットポインタを渡すことで実行されます。
2.デバイススロットのサブ状態ベクトルをホストスロットにチェックインする。
デバイススロットをホストスロットに戻す。この操作は、custatevecSubSVMigratorMigrate() の dstSubSV 引数にホストスロットポインタを渡すことで実行されます。
3.デバイススロット内のインデックスビットをスワップする。
ローカルインデックスビットをグローバルインデックスビット位置に移動する。この操作は、custatevecSwapIndexBits() APIを使用して実行されます。
グローバルインデックスビットは図3に示されるように移動されます。図3 (a-1) は、グローバルインデックスビット、q をローカライズするための最初の移行を示しています。0番目および1番目のサブ状態ベクトルがデバイススロットにコピーされ(チェックアウト)、qがデバイススロットのインデックスビットに移動します。次に、ゲートの適用や他の操作がデバイススロットのインデックスビットに含まれるqおよびローカルインデックスビットに対して適用されます。操作が完了すると、デバイススロットはホストスロットを更新するために戻されます(図3 (a-2))。状態ベクトルの最初の半分が更新されます(チェックイン)。同じ一連の手順が状態ベクトルの後半部分に対して実行されます(図3 (a-3, 4))。
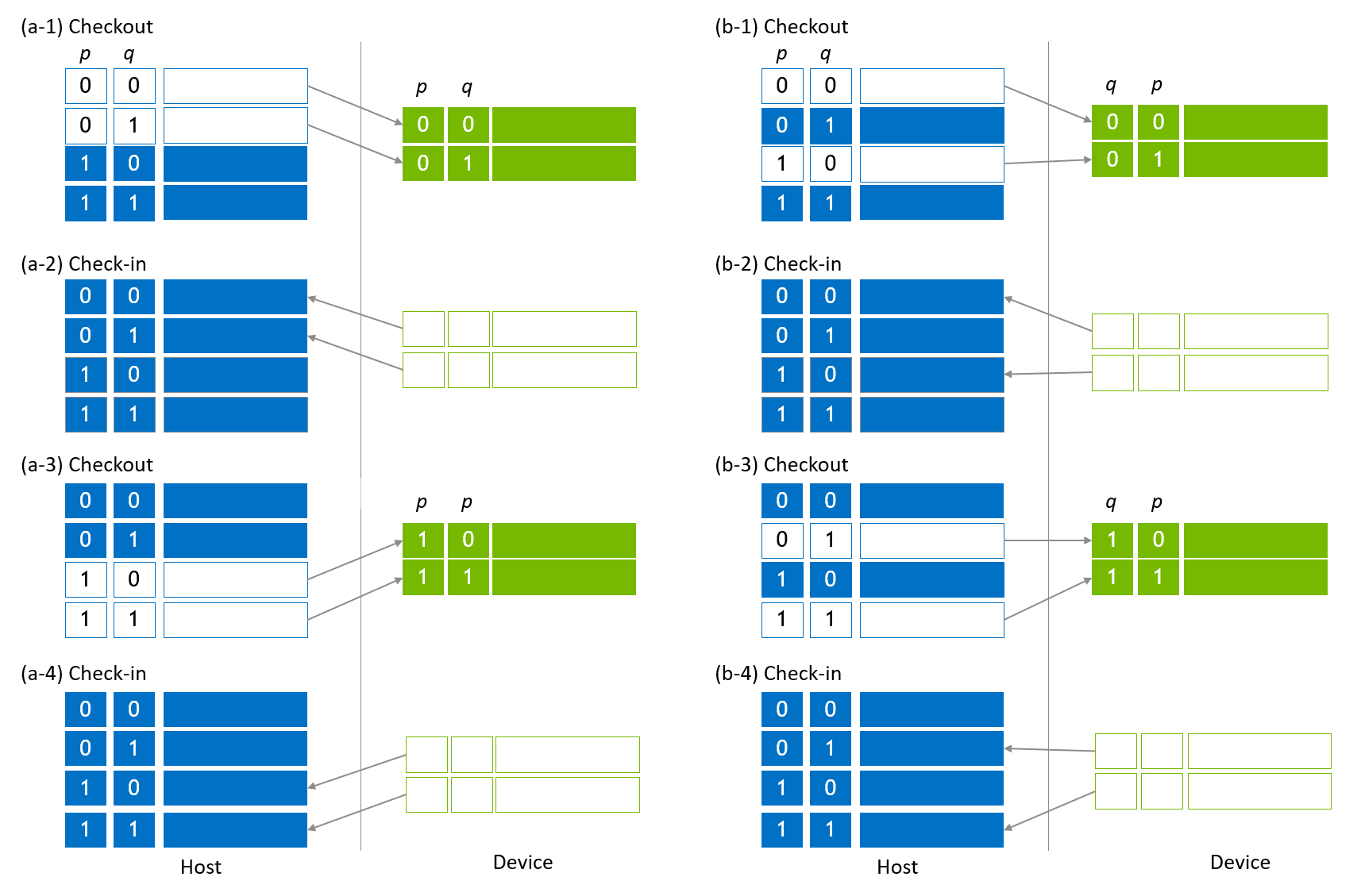
図3、引用:https://docs.nvidia.com/cuda/cuquantum/latest/custatevec/host_state_vector_migration.html
グローバルインデックスビット、pをデバイススロットに移動するためには、0番目および2番目のサブ状態ベクトルがデバイススロットにコピーされ、pがデバイススロットのインデックスビットに移動します(図3 (b-1))。図3 (b-2) - (b-4) に示されるような類似の手順が適用され、操作を完了します。
状態ベクトルの移行中には、チェックアウトとチェックインのサブ状態ベクトルを重ね合わせて、ホストとデバイス間の双方向転送(x86システム上のPCIeやGH200上のNVLink-C2C)を利用する最適化が行われます。図4の左側は、図3 (a-2) と (a-3) の一部を切り取ったものです。これら2つのステップは、図4の右側に示されるように1つのステップに統合されます。
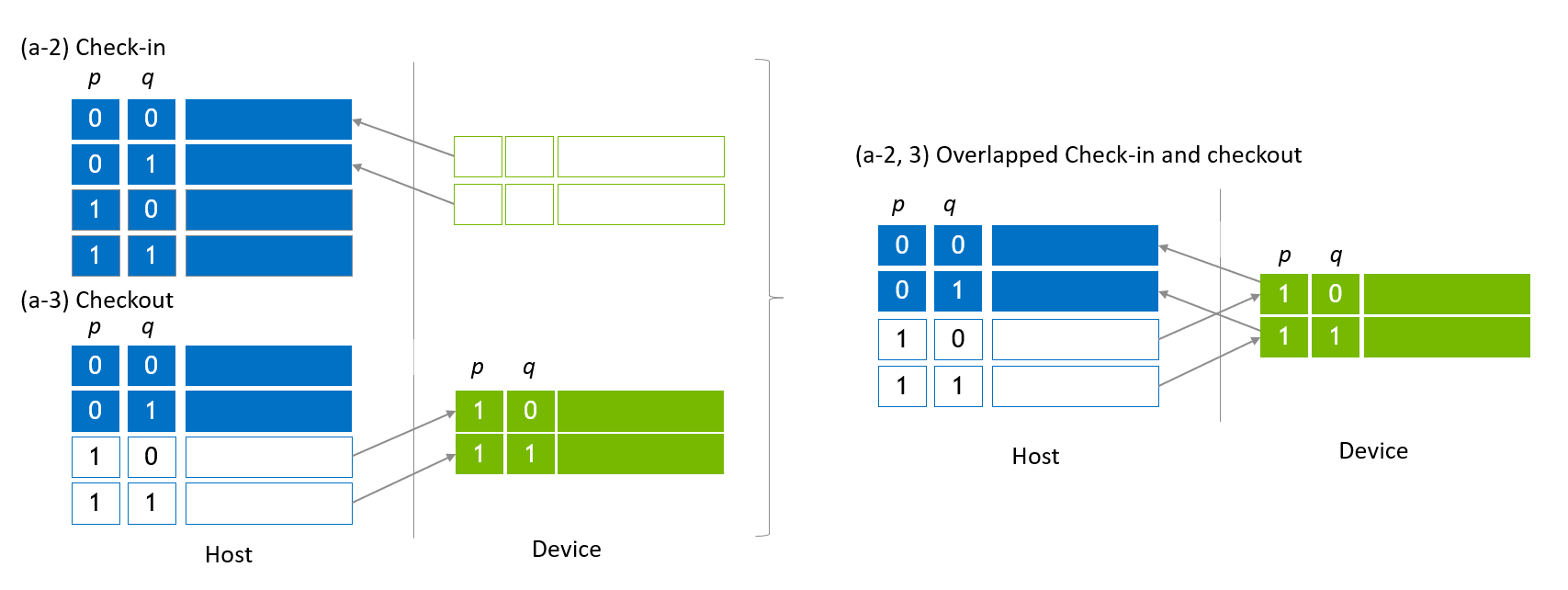
図4、引用:https://docs.nvidia.com/cuda/cuquantum/latest/custatevec/host_state_vector_migration.html
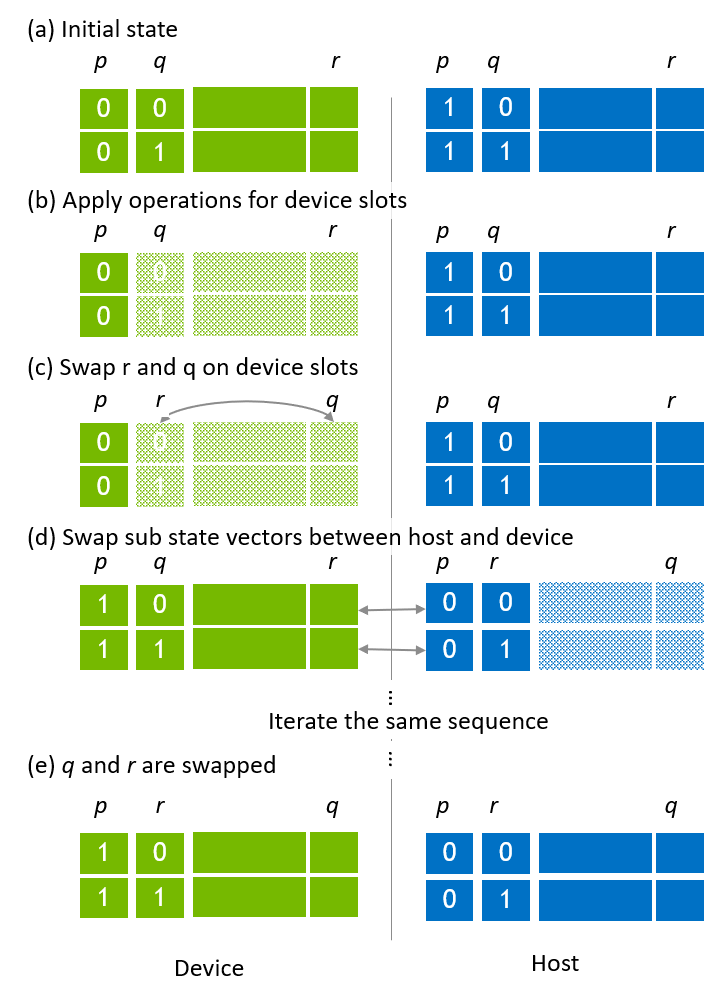
移行手順中にローカルインデックスビットをグローバルインデックスビットと交換するために、インデックスビットスワップが適用されます。図5に示されているように、左側の部分は初期状態のベクトル割り当てを示しており、ここでpとqはグローバルインデックスビットで、rはローカルインデックスビットのLSBであり、グローバルインデックスビットqと交換されます。
最初のチェックアウトステップは図3に示されている移行ステップと同じです。その後、qとrがスワップされ、qがローカルインデックスビットとして移動し、rがグローバルインデックスビットになります。このスワップはcuStateVec API、custatevecSwapIndexBits()によって操作されます。qとrをスワップした後、デバイススロットのサブステートベクトルがホストスロットにチェックインされます。残りのホストサブステートベクトルに対して同じことを適用することで、グローバルインデックスビットqとローカルインデックスビットrが交換されます。」
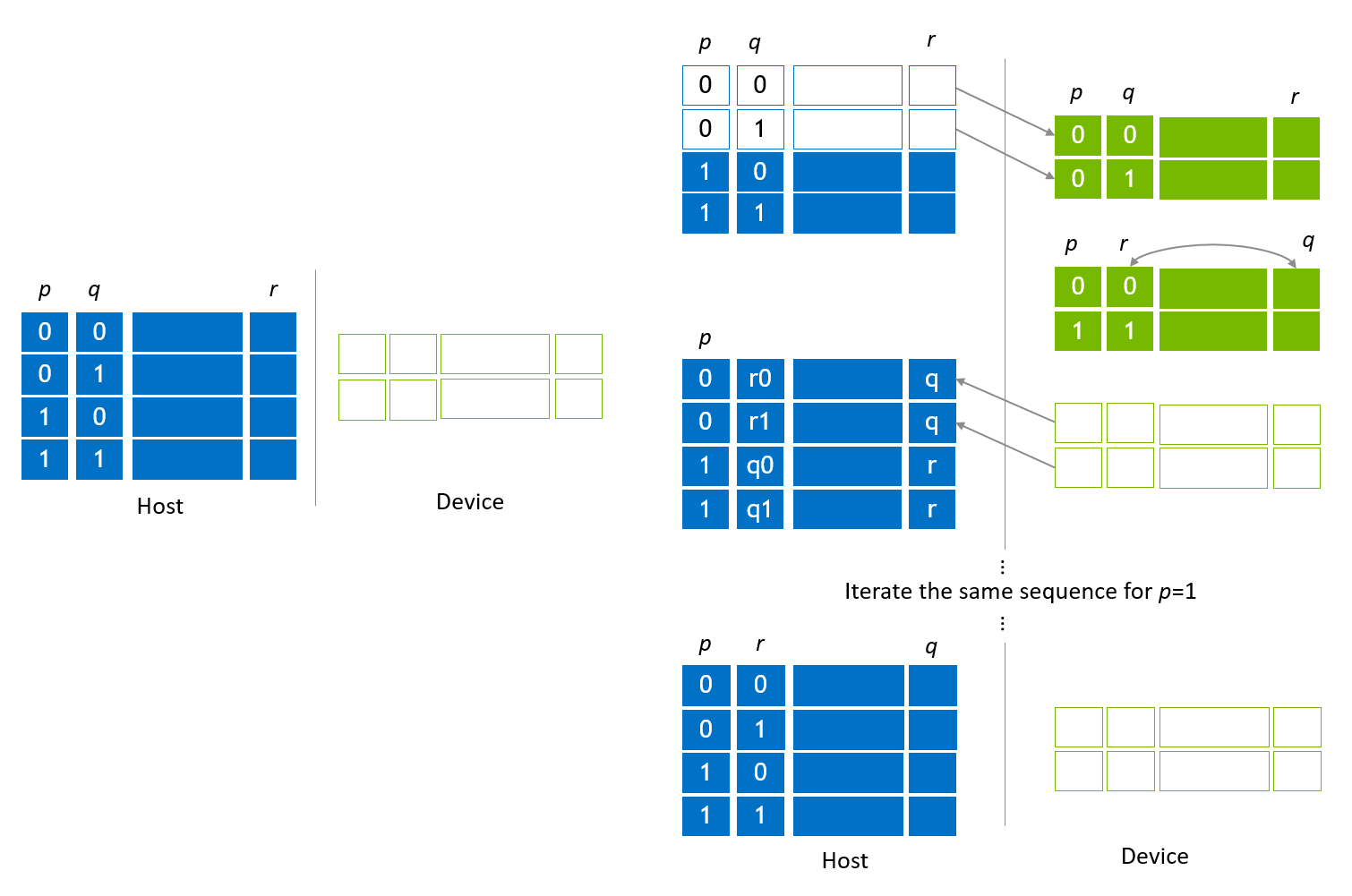
図5、引用:https://docs.nvidia.com/cuda/cuquantum/latest/custatevec/host_state_vector_migration.html
---------------
2. ホストとデバイススロットに状態ベクトルを割り当てる
第二のシナリオは、ホストとデバイスのメモリを利用し、状態ベクトルのサイズを最大化するためにそれらに状態ベクトルを割り当てることです。図6に示される例の割り当ては、各ホストとデバイススロットに2つのサブ状態ベクトルが配置されている最も単純なケースです。この例は、移行アルゴリズムを説明するために使用されます。ホスト上のサブ状態ベクトルの数を増やすことで、より大きな状態ベクトルを割り当てることができます。
例えば、NVIDIA H100 (80G) を使用して図6に示されるようにデバイススロットを割り当てる場合、デバイススロットの最大サイズは64GBです。ホスト状態ベクトルのサイズは同じであるため、ホスト状態ベクトルのサイズは128GB(ホスト上の64GB + デバイス上の64GB)になります。448GBのホストメモリを使用すると、状態ベクトルのサイズは512GBに増加します。
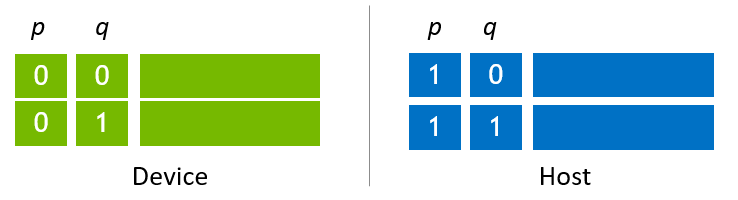
図6、引用:https://docs.nvidia.com/cuda/cuquantum/latest/custatevec/host_state_vector_migration.html
ホストとデバイスに割り当てられた状態ベクトルにおける、状態ベクトル移行のプリミティブはスワップであり、これは同じホスト状態ベクトルに対するチェックインとチェックアウトの重ね合わせと考えられます。custatevecSubSVMigratorは、custatevecSubSVMigratorMigrate() の srcSubSV と dstSubSV の引数に同じホストサブ状態ベクトルポインタを渡すことでサブ状態ベクトルをスワップします。
状態ベクトルの移行は、図7に示されるように実行されます。図7 (a) に示される最初のステップは、グローバルインデックスビット q がデバイススロット内でローカライズされている初期状態です。図7 (b) では、グローバルインデックスビット q とローカルインデックスビットを含むデバイススロットのインデックスビットに対して操作が適用されます。次に、ホストとデバイス間でサブ状態ベクトルがスワップされ、状態ベクトルの後半部分に対して操作が適用されます(図7 (c), (d))。
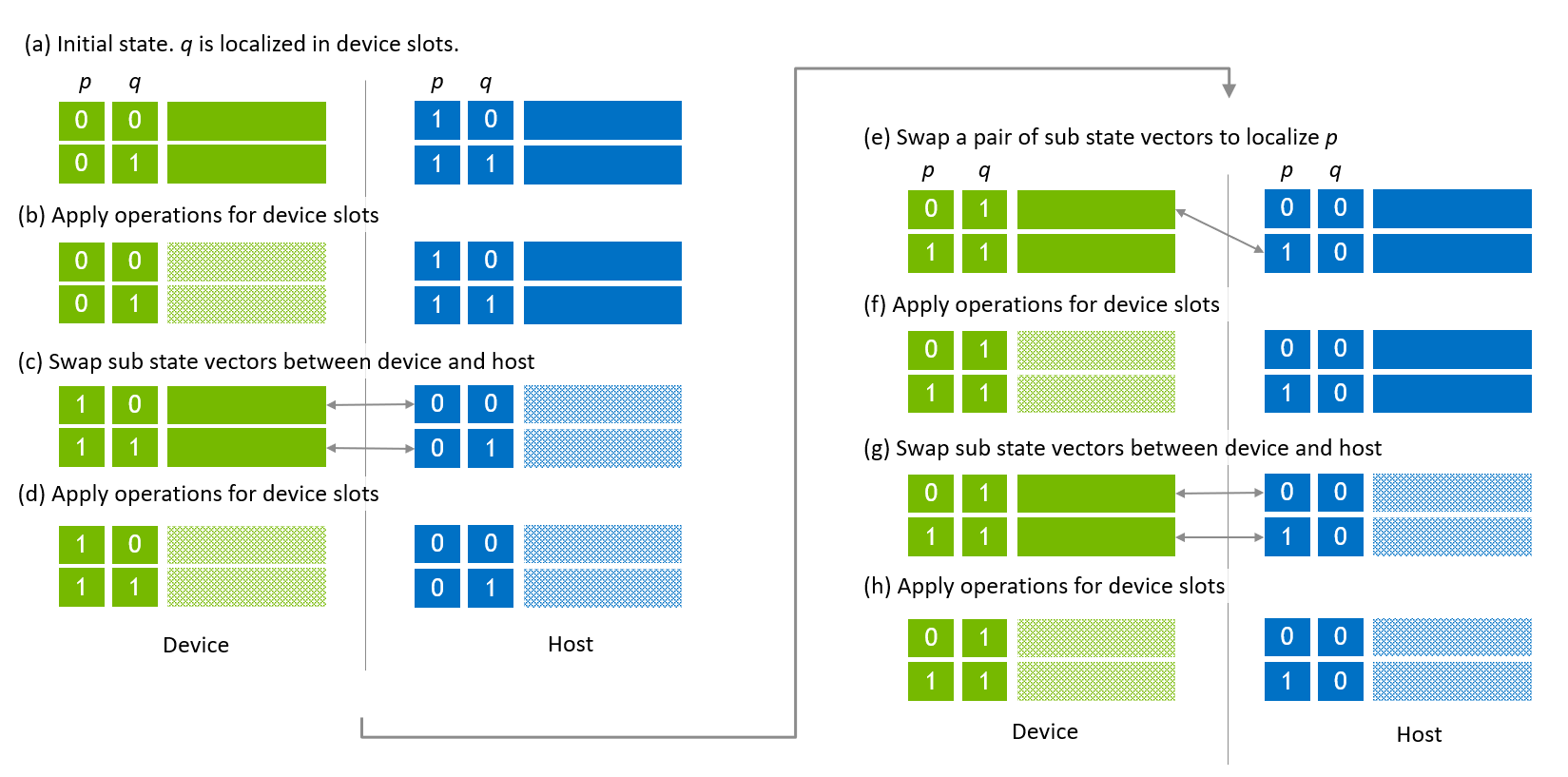
図7、引用:https://docs.nvidia.com/cuda/cuquantum/latest/custatevec/host_state_vector_migration.html
次の移行シーケンスは、グローバルインデックスビット p をローカライズし、操作を適用することを目指しています。最初の移行は、0番目のデバイスサブ状態ベクトルと1番目のホストサブ状態ベクトルをスワップすることです(図7 (e))。次に、状態ベクトルの最初の半分に対して操作が適用されます(図7 (f))。次の移行は、ホストとデバイス間でサブ状態ベクトルをスワップし、状態ベクトルの後半部分に対して操作が適用されます。
グローバルインデックスビットとローカルインデックスビットをスワップするためには、cuStateVec APIの custatevecSwapIndexBits() をホスト状態ベクトルに使用されるのと同じ方法で適用します。図8 (a) は、p と q がグローバルインデックスビットで、r がローカルインデックスビットの最下位ビット(LSB)である場合のホストとデバイスのサブ状態ベクトルの配置を示しています。操作を適用した後(図8 (b))、q と r がスワップされます(図8 (c))。次に、ホストとデバイス間でサブ状態ベクトルがスワップされます(図8 (d))。残りのサブ状態ベクトルに対して同じ手順を実行することで、q と r がスワップされます(図8 (e))。