Weekend Experiment: "Latent Space Diffusion Generation with MNIST and CIFAR-10 — Fast & Efficient Image Generation Using a Lightweight U-Net"
Recent diffusion models can produce high-quality images, but the computational cost remains significant, especially for high-resolution datasets, where both training and inference can be burdensome.
In this experiment, I used MNIST and CIFAR-10 as examples to try a lightweight U-Net implementation that performs diffusion in the latent space.
Why Use Latent Space?
Typical diffusion models denoise directly in pixel space. By working in latent space, we gain several advantages:
- Significant reduction in computation (lower resolution means fewer operations)
- Faster training (smaller U-Nets are sufficient)
- Smaller model size (easier to run on low-resource environments)
PCA-Based Latent Space Comparison (Without VAE)
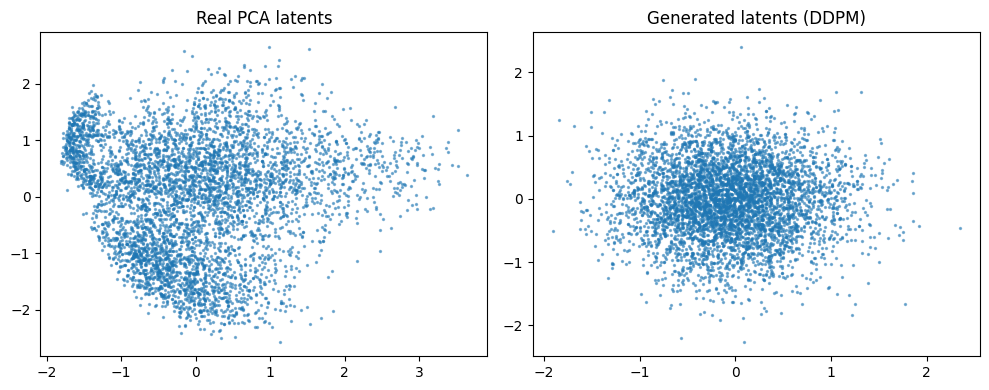
As a first step, I tried not using a VAE and instead compressing the images to two dimensions via PCA, then training a DDPM directly in that latent space.
Here, the original dataset (e.g., MNIST) is transformed into a 2D latent vector using PCA, and the diffusion model learns to reproduce that distribution.
After training, I compared the generated latent distribution with the original PCA latents.
The real data had complex shapes with class-specific biases and asymmetries, while the DDPM-generated results looked almost Gaussian, clustered toward the center.
This suggests that with short training, it’s hard to capture fine details of the distribution—likely due to limited model capacity and training steps.
Even so, this comparison was a useful baseline for understanding the behavior of latent space generation and prepared the ground for later experiments using VAE + latent diffusion.
Implementation Overview
- Compress images into a low-dimensional latent vector using a VAE
- Train a lightweight U-Net-based DDPM in latent space
- At inference, decode from the latent space back to images
I tested both MNIST (28×28, grayscale) and CIFAR-10 (32×32, RGB).
By adopting a lightweight U-Net, training and generation speeds improved greatly.
Results & Impressions
- MNIST – The shapes of digits were reasonably reproduced, and the process was very fast.
Images looked slightly blurry, but overall quality was sufficient.
This version was implemented in pure Python without using diffusers.

I also tried a proposed CNN version, which gave some improvements.

The contours became noticeably sharper.
- CIFAR-10 – The method also worked well with color data, running quickly even with a small U-Net.
The efficiency allowed more parameter tuning trials.
In earlier tests with direct pixel-space training, edges were sharper, but the speed advantage of latent-space processing is appealing.
I also mapped CIFAR-10 directly via PCA. It seemed more coherent than MNIST in this form:
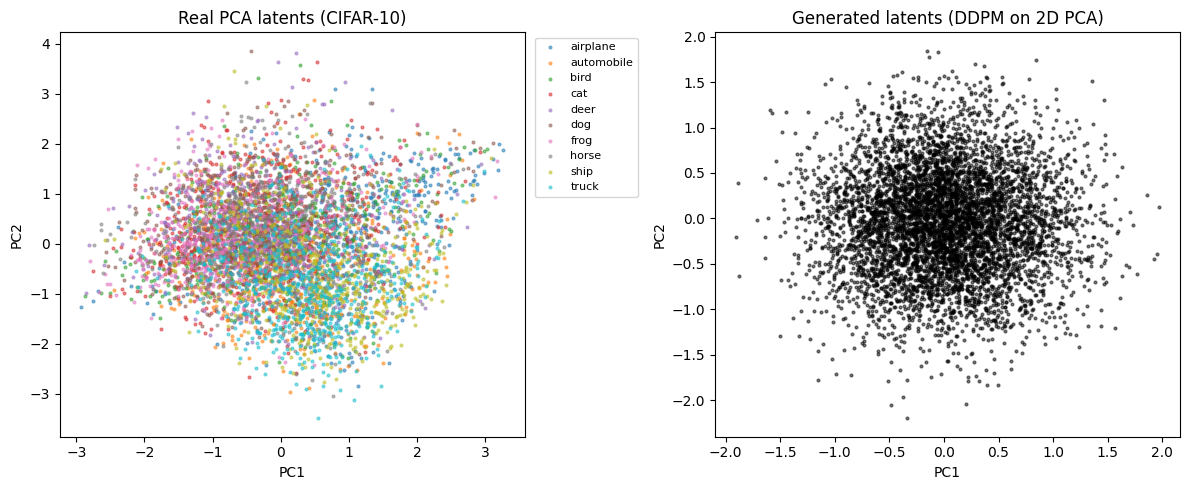
The images had recognizable structure but remained blurry.

When I tried making the model more powerful, the results suddenly turned into pure noise:
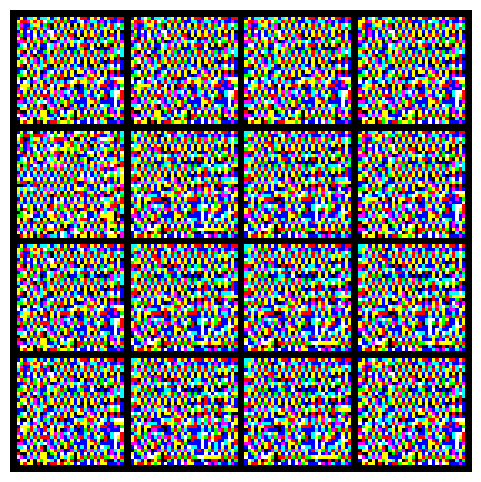
After further improvements, quality slightly recovered:

VAE reconstructions were reasonable:

Conclusion
Using latent space with a lightweight U-Net for diffusion strikes a good balance between quality and speed, making it ideal for exploratory experiments and prototyping.
For the next step, I plan to try conditional generation and higher-dimensional latent representations to further improve image quality.
In short: I’ve tried a lot, but with such small image sizes, it’s still hard to clearly see details—so I’ll challenge myself with larger images next time.