日本語の解説記事が見つかりませんでした。諦めて英語から行きます。
探してたら、GLaMとGLaMMがありますが、違うもののようです。今回はGLaMMです。
GLaMM: Pixel Grounding Large Multimodal Model
Hanoona Rasheed, Muhammad Maaz, Sahal Shaji, Abdelrahman Shaker, Salman Khan, Hisham Cholakkal, Rao M. Anwer, Erix Xing, Ming-Hsuan Yang, Fahad S. Khan
https://arxiv.org/abs/2311.03356
英語の解説記事は一つあったのですが、日本語に戻すのが大変そうなので、それならと元の公式の説明を探した方が良いと思いました。
プロジェクトのページを見つけました。
https://mbzuai-oryx.github.io/groundingLMM/
みてみます。元の論文も読みやすそうではありますが、今回はプロジェクトページを中心に見ます。
もうなんかChatGPTがほとんど説明してくれてしまいますが。。。途中を省略しながら説明を見ていきます。
「Grounding Large Multimodal Model(GLaMM)は、画像と画像の領域の両方の入力を処理する柔軟性を備えた、エンドツーエンドでトレーニングされた大規模マルチモーダルモデル(LMM)です。これにより、フレーズグラウンディング、参照表現セグメンテーション、ビジョン言語会話を組み合わせた新しい統一タスクであるGrounded Conversation Generationが可能になります。詳細なリージョン理解、ピクセルレベルのグラウンディング、および会話能力を備えたGLaMMは、ユーザーが提供する視覚入力に対して、オブジェクト、オブジェクトの部分、属性、関係、全体的なシーン理解など、複数の粒度レベルでの多様な対話能力を提供します。」
いくつか聞き慣れない文言が出てきたので、確認します。
--------
「フレーズグラウンディング」は、自然言語処理(NLP)とコンピュータビジョン(CV)が交差する研究分野で用いられる用語です。この概念は、特定の言語的表現(通常はテキストで与えられたフレーズや文)が、画像やビデオ内の具体的な物体や領域にどのように対応するかを特定するプロセスを指します。
たとえば、画像に含まれるテキストの記述(例えば「赤い車」や「木の下で遊んでいる子供」など)が与えられた場合、フレーズグラウンディングのタスクは、その記述が指す具体的な画像の領域(この場合は赤い車や木の下にいる子供)を特定し、マッピングすることです。
--------
「参照表現セグメンテーション」は、自然言語処理(NLP)とコンピュータビジョン(CV)の分野におけるタスクの一つです。このタスクの目的は、特定の言語表現(「参照表現」と呼ばれる)が指し示す画像内の具体的なオブジェクトや領域を正確に識別し、セグメンテーション(つまり、そのオブジェクトや領域の輪郭や境界を特定すること)することです。
具体的には、与えられた画像と関連する記述(例えば、「緑の木の近くにいる白い犬」)に基づき、その記述に対応する画像の具体的な部分(この場合、特定の犬がいる場所)を識別し、その境界を描き出すことが求められます。
この翻訳では、GLaMMがエンドツーエンドで訓練された大規模マルチモーダルモデルであり、画像およびリージョン入力の処理において柔軟性を持つ視覚的グラウンディング能力を提供することを説明しています。また、GLaMMがGrounded Conversation Generationという新しいタスクを可能にし、さまざまな粒度で視覚入力との対話を可能にする能力を持っていることが強調されています。
--------
まぁ、つまり言語と画像内の物体や領域を繋ぎ込んだということみたいです。
次に特徴です。三つありましたが前半二つはすでに紹介された話とかぶってます。最後の一つは、
GranDデータセットの作成
モデルのトレーニングと評価を容易にするために、「GranD - Grounding-anything Dataset」という大規模で密にアノテートされたデータセットを作成します。自動アノテーションパイプラインと検証基準を使用して開発され、810Mの領域に根ざす750万のユニークなコンセプトを含んでいます。さらに、既存のオープンソースデータセットを再利用することで、GCGタスクに特化して設計された高品質のデータセット「GranD-f」を製作しました。
ということで、データセットの作成機能というのを兼ね備えているようです。
次にモデルです。
このテキストを日本語に翻訳すると以下のようになります:
モデルは5つの部分からなるようです。
具体的なアーキテクチャは論文中から探して記述しています。
この英語の解説記事にはアーキテクチャの具体的な記述は見つかりませんでした。
i) グローバルイメージエンコーダー(ViT-H/14 CLIP)
ii) リージョンエンコーダー(CLIPをベースに作っている)
iii) 大規模マルチモーダルモデル(LLM)(vicuna)
iv) グラウンディングイメージエンコーダー(SAM)
v) ピクセルデコーダー(SAMベースのもの)
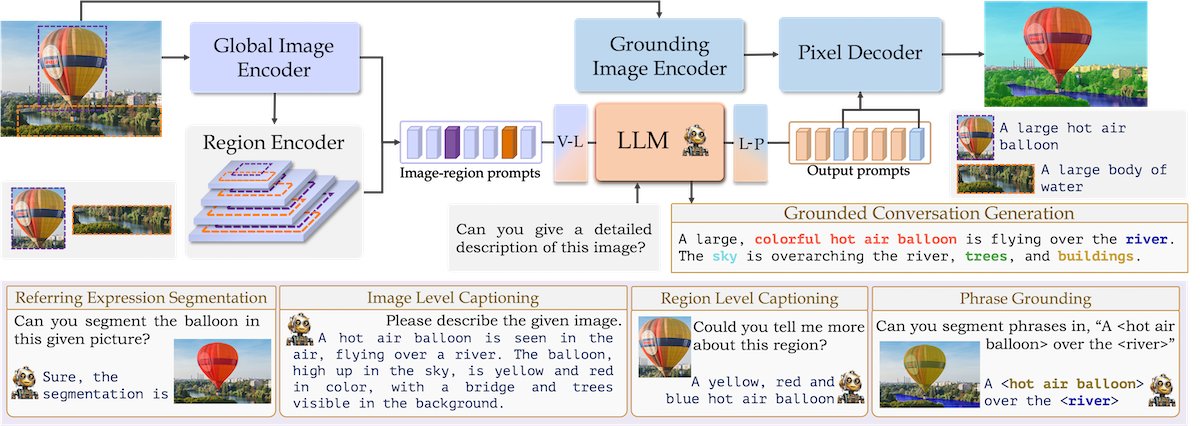
出典:https://mbzuai-oryx.github.io/groundingLMM/
最初は左から画像全体のGlobal Image Encoder、そして、領域ごとに抽出されたオブジェクトのRegion Encoderが付いてます。そっから Image-region promptsというプロンプトに。そこからvision to languageレイヤーで変換されてLLMに入力、テキストプロンプトが入り、GCGと呼ばれる画像を含む会話が作成、並行して出力のプロンプトが、Pixelデコーダーに入るのですが、同時に元の全体画像もエンコーダーからpixelデコーダーに入り、最終的な説明付きのセグメンテーションが作成されます。
モデルの詳細は、論文を読まないとわからないと感じました。
次行きます。このモデルはマルチモーダルの統合モデルのようで、単独というよりも言語と画像領域を組み合わせた様々な作業ができるようです。以下は昨日の組み合わせになっててとにかくたくさんあります。紹介しきれないので、どんどん行きます。
Grounding-anything Dataset (GranD)
「詳細なリージョンレベルの理解には、画像の領域に対する大規模なアノテーションを収集するという手間のかかるプロセスが必要です。手作業によるラベリングの労力を軽減するために、大規模なGrounding-anything Datasetをアノテートする自動化パイプラインを提案します。専用の検証ステップを組み込んだ自動化パイプラインを活用することで、GranDは合計810Mの領域にアンカーされた750万のユニークなコンセプトを含み、それぞれにセグメンテーションマスクが付いています。」

出典:https://mbzuai-oryx.github.io/groundingLMM/
自動アノテーションパイプラインは、セグメンテーションマスクと共に、オブジェクトに対して複数の意味的なタグと属性を提供します。詳細なキャプションは視覚シーンを詳細に記述し、テキストの一部が対応するオブジェクトにグラウンドされます。追加のコンテキストは、観察されるものを超えて、シーンのより深い理解を提供します。

出典:https://mbzuai-oryx.github.io/groundingLMM/
ほかにも例がありますが、飛ばしていきます。
Grounded Conversation Generation用のGranD-fの構築
微調整段階における高品質データ向けのGranD-f。GCGタスクに特に設計されたこのデータセットは、約214Kの画像に基づいたテキストペアを含んでいます。これらのうち、2.6Kのサンプルが検証用に、5Kがテスト用に予約されています。GranD-fは、一つのサブセットが手動でアノテートされ、もう一つのサブセットが既存のオープンソースデータセットを再利用して導出された、二つの主要なコンポーネントで構成されています。
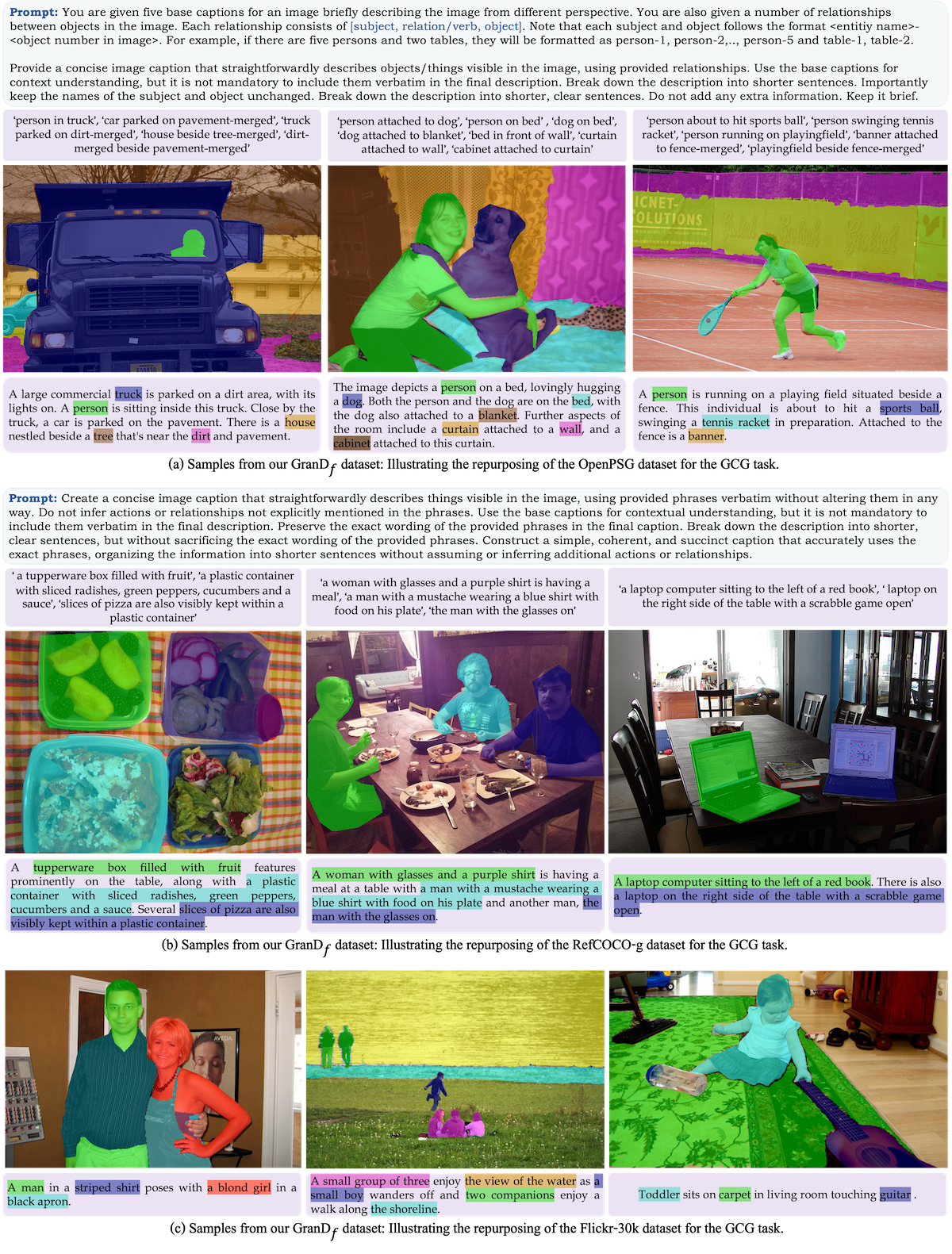
出典:https://mbzuai-oryx.github.io/groundingLMM/
Grounded Conversation Generation (GCG)
GCGタスクの目的は、画像内の対応するセグメンテーションマスクに直接結び付けられた特定のフレーズを含む画像レベルのキャプションを構築することです。GCGタスクを導入することで、テキストと視覚の理解の間のギャップを埋め、モデルの自然言語キャプショニングとともに細かな視覚的グラウンディングの能力を向上させます。

出典:https://mbzuai-oryx.github.io/groundingLMM/
参照表現セグメンテーション
このタスクでは、モデルは画像とそれに関連するテキストベースの参照表現を受け取り、対応するセグメンテーションマスクを出力します

出典:https://mbzuai-oryx.github.io/groundingLMM/
このテキストを日本語に翻訳すると以下のようになります:
リージョンレベルのキャプショニング
参照表現、またはリージョン固有のキャプションを生成することです。モデルは、画像、指定されたリージョン、および付随するテキストを入力し、指定されたリージョンについての質問に応答するタスクを行います。
出典:https://mbzuai-oryx.github.io/groundingLMM/
画像キャプショニングGLaMMは、画像キャプショニングに特化した最近のモデルや他の大規模マルチモーダルモデル(LMM)と比較して有利なパフォーマンスを提供します。

出典:https://mbzuai-oryx.github.io/groundingLMM/
ついに最後の機能です。。。
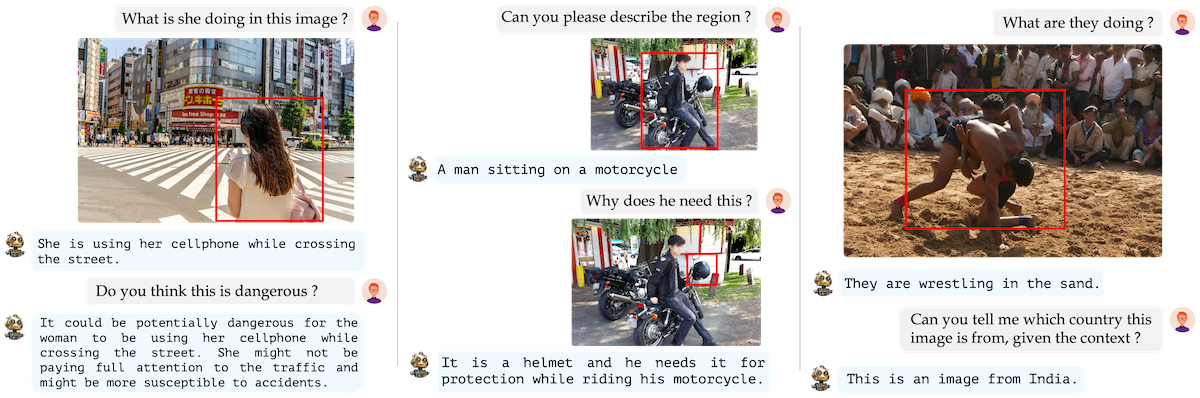
会話形式の質問応答
GLaMMがマルチターンの対話に参加し、詳細な説明を提供し、リージョン固有の問い合わせに応答し、グラウンドされた会話を提示している様子を示しています。

出典:https://mbzuai-oryx.github.io/groundingLMM/
とにかくマルチモーダルで画像と言語を結びつける統合フレームワーク的なモデルの集合ということがよくわかりました。以上です。