量子コンピュータを利用した強化学習について、今回はtensorflowから二種類を紹介したいと思います。今後の勉強会ではこの二種類をより深堀したいとおもいます。
1,Policy-Gradient型
2,Deep-Q-Learning型
さっそく見てみましょう。
参考
tensorflow quantumのページを張ります。
https://www.tensorflow.org/quantum/tutorials/quantum_reinforcement_learning?hl=ja
論文は
Parametrized quantum policies for reinforcement learning
https://arxiv.org/abs/2103.05577
Quantum agents in the Gym: a variational quantum algorithm for deep Q-learning
https://arxiv.org/abs/2103.15084
利用するライブラリ
今回はOpenAIGymのCartPoleを利用します。
http://gym.openai.com/envs/CartPole-v1/
概略
二つの種類の強化学習の式を簡単に概要を見ながら、PQCと呼ばれるパラメータ付きの量子回路の学習方法を超概略で確認します。
PQC
パラメータ化量子回路は、量子回路の中に任意回転ゲート(1でも2量子ビットでも)を取り入れ、その角度を変更しながら回路の計算結果を変えます。NISQと呼ばれるエラーありの計算ではとてもポピュラーなやり方です。角度の最適化には普通のコンピュータを使いますので、実質的に学習は普通のコンピュータで行います。
始める前に
今回の強化学習では量子回路での計算結果を期待値の形として取り出し、それを使って二種類の強化学習に適用します。角度パラメータを使ってデータを表現しますが、接続性を含めて表現を高めるために、単一の量子ビットの任意回転とCZを使ってデータの表現を高めるという手法があるようです。これを使って3つのエリアを使って入力のデータを表現し、拡張します。
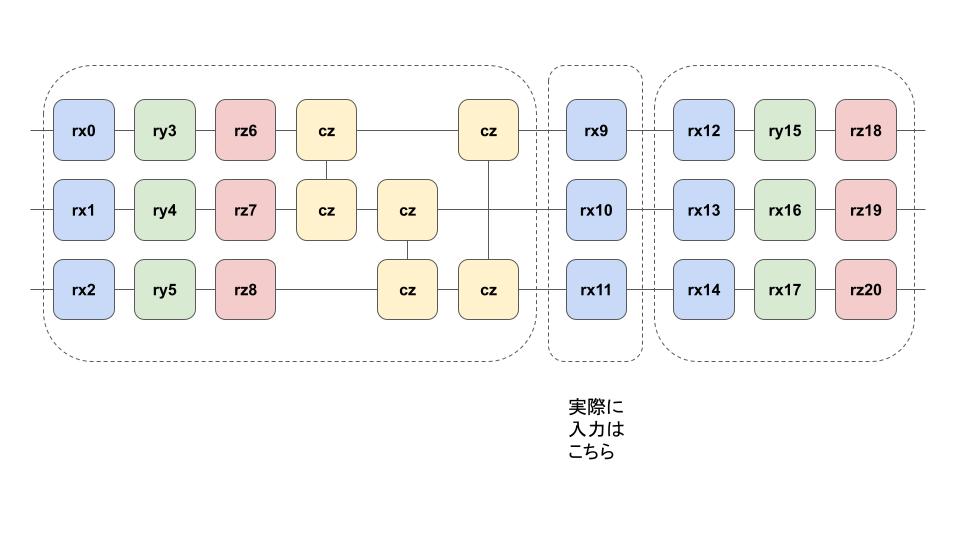
参考:https://www.tensorflow.org/quantum/tutorials/quantum_reinforcement_learning?hl=ja
実際にはこちらを複数回繰り返すことによって、
1,Policy-Gradient型
上記のパラメータ化量子回路を使ってstateを量子回路に組み込み、計算結果を出せます。Policy Gradientタイプはこれらの計算の期待値を利用して方策を決めるタイプのようです。
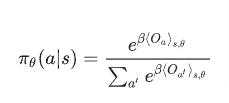
参考:https://www.tensorflow.org/quantum/tutorials/quantum_reinforcement_learning?hl=ja
学習時の損失関数は、
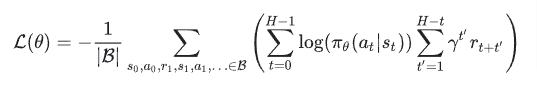
参考:https://www.tensorflow.org/quantum/tutorials/quantum_reinforcement_learning?hl=ja
なんかパラメータは3つの異なる学習率で実行されるので、3つ最適化ソルバーを用意すると書いてあります。詳しいことは今後個別の勉強会で学んでみたいと思います。
2,Deep-Q-Learning型
こちらは期待値をQ関数を使います。損失関数含めて、下記のとおりです。

参考:https://www.tensorflow.org/quantum/tutorials/quantum_reinforcement_learning?hl=ja
全体的には処理は重そうですし、シンプルな問題でも解くのは大変そうですが、探求心はそそられますので、勉強会は続けます。以上です。